TL;DR: I got a lot of stuff right and a lot of stuff wrong. My Brier score (a measure of forecasting skill) was .22, which is slightly better than chance but not great. My forecasts were most accurate in areas that I’m familiar with, and areas where quantitative extrapolation was possible; they were less accurate in cases where I relied on discussions with a small number of bullish experts or on a vague sense of the “hotness” of certain sub-fields of AI.
Introduction
I’ve written a fair amount about the issue of progress in AI and forecasts thereof, including this paper and this blog post last year. This topic is intrinsically interesting to me, and seems neglected relative to its interestingness--most AI-related papers are about how to make capabilities a bit better rather than trying to understand the relative contributions of hardware, algorithmic improvements, data, fine-tuning, etc. to past performance increases, or projecting these into the future.
The topic also seems important, because lots of people are rightly concerned about the societal implications of AI, which in turn hinges partially on how quickly certain developments will arise. And in light of substantial expert disagreement on the future of AI (including both the timing of developments and its social implications), it seems like it should be a topic of a lot of scholarly interest. There has been some movement towards taking it more seriously in the last year or so, including the EFF AI Progress Measurement Project and the AI Index, but as researchers like me are wont to say, more research is still needed.
Besides my prior paper on this topic and some ongoing research, I’ve tried to contribute to this discussion via blog posts and Twitter, by putting specific falsifiable AI forecasts on record, so that they can be evaluated in the future by myself and others. I also encourage others to do the same. I focus on short-term forecasts so that there is a feedback loop in a reasonable period of time regarding the reliability and calibration of one’s forecasts, and because, a priori, short-term forecasts seem more likely to be reliable than long-term ones. In this blog post, I’ll try to resolve all of my forecasts made in early 2017 and discuss some takeaways I’ve arrived at from analyzing them.
As alluded to in the TL;DR above (no need to read it if you haven’t already), they’re a mixed bag. Overall, I’ve updated a bit in the direction of not trusting my own short-term forecasts, or those of others about whom I have even less information regarding their extent of overconfidence (a pervasive problem in forecasting and human judgment more generally, as documented in other domains).
Methods
Resolving my 2017 forecasts was a lot easier than resolving my 2016 forecasts, because I put most of the 2017 ones in a single blog post and they were mostly pretty objective. But a lot of ambiguities arose, some expected (e.g. a forecast about “impressive” progress) and some unexpected (e.g. I forgot to specify some aspects of how quantitative Atari forecasts should be evaluated). To help with my evaluation process, I solicited help from relevant experts, especially Sebastian Ruder on the topic of transfer learning and Marc Bellemare on the topic of Atari AI. Thank you, Seb and Marc, for your help!
I will try to be explicit below about my decision process for arriving at True/False designations for specific forecasts, and my overall Brier score (a measurement of forecasting skill), but I don’t expect to totally eliminate ambiguity. I also don’t want this blog post to be super boring, though, so I’ll inevitably leave some things out, and feel free to get in touch with me to discuss more. One can pretty easily plug in different values for my forecasts and arrive at different conclusions for how well I did in 2017.
Overview of Results
Without further ado, here’s a rapid-fire summary of how the forecasts fared. In the next section, I’ll elaborate on each forecast, what actually happened in 2017 in the related technical area, and how a true/false determination was made.
Best median Atari score between 300 and 500% at end of 2017 (confidence: 80%)
TRUE
Comment: See caveats regarding compute requirements.
Best median Atari score between 400 and 500% at end of 2017 (confidence: 60%)
TRUE
Comment: See caveats regarding compute requirements.
Best mean Atari score between 1500% and 4000% at end of 2017 (confidence: 60%)
TRUE
Comment: See caveat regarding compute requirements below.
No human-level or superintelligent AI (confidence: 95%)
TRUE
Comment: Freebie.
Superhuman Montezuma’s Revenge AI (confidence: 70%)
FALSE
Comment: Resolved as false despite mild ambiguity.
Superhuman Labyrinth performance (confidence: 60%)
TRUE
Comment: Could be broken into two separate predictions for mean and median but I opted not to do that to avoid favoring self.
Impressive transfer learning (confidence: 70%)
FALSE
Comment: Under-specified; resolved as false based on expert feedback.
(sub-prediction of the above) Impressive transfer learning aided by EWC or Progressive Nets (confidence: 60%)
N/A
Comment: Conditional on the above being false, the probability of this one being true is zero, so it is not being counted towards the Brier score calculation.
Speech recognition essentially solved (confidence: 60%)
FALSE
Comment: Did not check with experts but seems unambiguously false for a broad sense of “human-level” speech recognition (especially noisy, accented, and/or multispeaker environments).
No defeat of AlphaGo by human (confidence: 90%)
TRUE
Comment: Seems like a freebie in retrospect given AlphaGo Zero and AlphaZero but perhaps wasn’t obvious at the time in light of Lee Sedol’s game 4 performance.
StarCraft progress via deep learning (confidence: 60%)
FALSE
Comment: Under a somewhat plausible interpretation of the original forecast, this could have been resolved as true, since by some metrics it occurred (good performance attained on StarCraft sub-tasks with deep learning). Using the specific measure of progress I mentioned (performance in the annual StarCraft AI tournament), the forecast was barely false (4th place bot in the annual competition used deep learning, vs. 3rd or above as I said).
Professional StarCraft player beaten by AI system by end of 2018 (confidence: 50%)
TOO SOON TO RESOLVE
More efficient Atari learning (confidence: 70%)
TRUE
Comment: Some ambiguity based on the available data on frames used, performance at different stages of training, etc. but leaning towards true. See comments below.
Discussion of Individual Forecasts
As the above rapid-fire summary suggests, there were several trues and several falses, but that doesn’t give a complete picture of forecasting ability, because one also has to take the confidence level for each forecast into account. I’ll return to that when I calculate my Brier score below. But first, I’ll go through each forecast one by one and comment briefly on what the forecast meant, what actually happened, and how I resolved the forecast. If you’re not interested in a specific forecast, feel free to skip each subsection below or the whole section, as I’ll return to general takeaways later.
Best median Atari score between 300 and 500% at end of 2017 (confidence: 80%)
What I meant: I was referring here (as is pretty clear from the original blog post and the relevant literature) to the best median score, normalized to a human scale (where 0 is random play and 100 is a professional game tester working for DeepMind), attained by a single machine learning system playing ~49-57 Atari games with a single set of hyperparameters across games. This does not mean a single trained system that can play a bunch of games, but a single untrained system which is copied and then individually trained on a bunch of games in parallel. The median performance is arguably more meaningful as a measure than the mean, due to the possibility of crazily high scores on individual games. But mean scores will be covered below, too.
Why did I say 300-500%? Simple: I just extrapolated the mean and median trends into the future on a graph and eyeballed it. 300-500% seemed reasonably conservative (despite representing a significant improvement over the previous state of the art in 2016 of ~150%, or ~250% with per-game hyperparameter tuning). 400-500% was a more specific forecast, so I gave that range less confidence than 300-500% (see next forecast below).
Introduction
I’ve written a fair amount about the issue of progress in AI and forecasts thereof, including this paper and this blog post last year. This topic is intrinsically interesting to me, and seems neglected relative to its interestingness--most AI-related papers are about how to make capabilities a bit better rather than trying to understand the relative contributions of hardware, algorithmic improvements, data, fine-tuning, etc. to past performance increases, or projecting these into the future.
The topic also seems important, because lots of people are rightly concerned about the societal implications of AI, which in turn hinges partially on how quickly certain developments will arise. And in light of substantial expert disagreement on the future of AI (including both the timing of developments and its social implications), it seems like it should be a topic of a lot of scholarly interest. There has been some movement towards taking it more seriously in the last year or so, including the EFF AI Progress Measurement Project and the AI Index, but as researchers like me are wont to say, more research is still needed.
Besides my prior paper on this topic and some ongoing research, I’ve tried to contribute to this discussion via blog posts and Twitter, by putting specific falsifiable AI forecasts on record, so that they can be evaluated in the future by myself and others. I also encourage others to do the same. I focus on short-term forecasts so that there is a feedback loop in a reasonable period of time regarding the reliability and calibration of one’s forecasts, and because, a priori, short-term forecasts seem more likely to be reliable than long-term ones. In this blog post, I’ll try to resolve all of my forecasts made in early 2017 and discuss some takeaways I’ve arrived at from analyzing them.
As alluded to in the TL;DR above (no need to read it if you haven’t already), they’re a mixed bag. Overall, I’ve updated a bit in the direction of not trusting my own short-term forecasts, or those of others about whom I have even less information regarding their extent of overconfidence (a pervasive problem in forecasting and human judgment more generally, as documented in other domains).
Methods
Resolving my 2017 forecasts was a lot easier than resolving my 2016 forecasts, because I put most of the 2017 ones in a single blog post and they were mostly pretty objective. But a lot of ambiguities arose, some expected (e.g. a forecast about “impressive” progress) and some unexpected (e.g. I forgot to specify some aspects of how quantitative Atari forecasts should be evaluated). To help with my evaluation process, I solicited help from relevant experts, especially Sebastian Ruder on the topic of transfer learning and Marc Bellemare on the topic of Atari AI. Thank you, Seb and Marc, for your help!
I will try to be explicit below about my decision process for arriving at True/False designations for specific forecasts, and my overall Brier score (a measurement of forecasting skill), but I don’t expect to totally eliminate ambiguity. I also don’t want this blog post to be super boring, though, so I’ll inevitably leave some things out, and feel free to get in touch with me to discuss more. One can pretty easily plug in different values for my forecasts and arrive at different conclusions for how well I did in 2017.
Overview of Results
Without further ado, here’s a rapid-fire summary of how the forecasts fared. In the next section, I’ll elaborate on each forecast, what actually happened in 2017 in the related technical area, and how a true/false determination was made.
Best median Atari score between 300 and 500% at end of 2017 (confidence: 80%)
TRUE
Comment: See caveats regarding compute requirements.
Best median Atari score between 400 and 500% at end of 2017 (confidence: 60%)
TRUE
Comment: See caveats regarding compute requirements.
Best mean Atari score between 1500% and 4000% at end of 2017 (confidence: 60%)
TRUE
Comment: See caveat regarding compute requirements below.
No human-level or superintelligent AI (confidence: 95%)
TRUE
Comment: Freebie.
Superhuman Montezuma’s Revenge AI (confidence: 70%)
FALSE
Comment: Resolved as false despite mild ambiguity.
Superhuman Labyrinth performance (confidence: 60%)
TRUE
Comment: Could be broken into two separate predictions for mean and median but I opted not to do that to avoid favoring self.
Impressive transfer learning (confidence: 70%)
FALSE
Comment: Under-specified; resolved as false based on expert feedback.
(sub-prediction of the above) Impressive transfer learning aided by EWC or Progressive Nets (confidence: 60%)
N/A
Comment: Conditional on the above being false, the probability of this one being true is zero, so it is not being counted towards the Brier score calculation.
Speech recognition essentially solved (confidence: 60%)
FALSE
Comment: Did not check with experts but seems unambiguously false for a broad sense of “human-level” speech recognition (especially noisy, accented, and/or multispeaker environments).
No defeat of AlphaGo by human (confidence: 90%)
TRUE
Comment: Seems like a freebie in retrospect given AlphaGo Zero and AlphaZero but perhaps wasn’t obvious at the time in light of Lee Sedol’s game 4 performance.
StarCraft progress via deep learning (confidence: 60%)
FALSE
Comment: Under a somewhat plausible interpretation of the original forecast, this could have been resolved as true, since by some metrics it occurred (good performance attained on StarCraft sub-tasks with deep learning). Using the specific measure of progress I mentioned (performance in the annual StarCraft AI tournament), the forecast was barely false (4th place bot in the annual competition used deep learning, vs. 3rd or above as I said).
Professional StarCraft player beaten by AI system by end of 2018 (confidence: 50%)
TOO SOON TO RESOLVE
More efficient Atari learning (confidence: 70%)
TRUE
Comment: Some ambiguity based on the available data on frames used, performance at different stages of training, etc. but leaning towards true. See comments below.
Discussion of Individual Forecasts
As the above rapid-fire summary suggests, there were several trues and several falses, but that doesn’t give a complete picture of forecasting ability, because one also has to take the confidence level for each forecast into account. I’ll return to that when I calculate my Brier score below. But first, I’ll go through each forecast one by one and comment briefly on what the forecast meant, what actually happened, and how I resolved the forecast. If you’re not interested in a specific forecast, feel free to skip each subsection below or the whole section, as I’ll return to general takeaways later.
Best median Atari score between 300 and 500% at end of 2017 (confidence: 80%)
What I meant: I was referring here (as is pretty clear from the original blog post and the relevant literature) to the best median score, normalized to a human scale (where 0 is random play and 100 is a professional game tester working for DeepMind), attained by a single machine learning system playing ~49-57 Atari games with a single set of hyperparameters across games. This does not mean a single trained system that can play a bunch of games, but a single untrained system which is copied and then individually trained on a bunch of games in parallel. The median performance is arguably more meaningful as a measure than the mean, due to the possibility of crazily high scores on individual games. But mean scores will be covered below, too.
Why did I say 300-500%? Simple: I just extrapolated the mean and median trends into the future on a graph and eyeballed it. 300-500% seemed reasonably conservative (despite representing a significant improvement over the previous state of the art in 2016 of ~150%, or ~250% with per-game hyperparameter tuning). 400-500% was a more specific forecast, so I gave that range less confidence than 300-500% (see next forecast below).
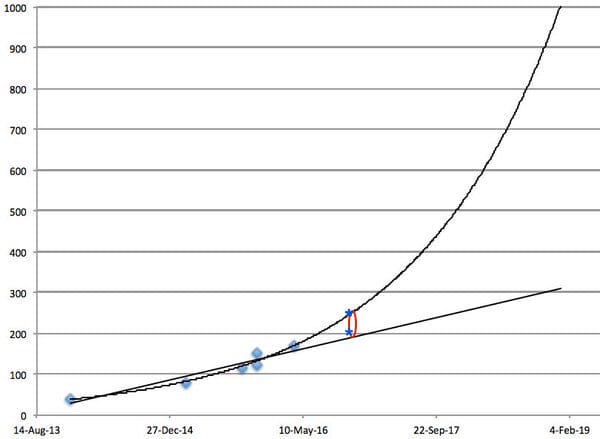
(median project figure taken from my blog post last year)
What happened: There was a lot of progress in Atari AI this year. For a more comprehensive summary of algorithmic improvements bearing on Atari progress in the past few years, as well as remaining limitations, see e.g. this, this, and this. I’ll mention two developments of particular relevance here.
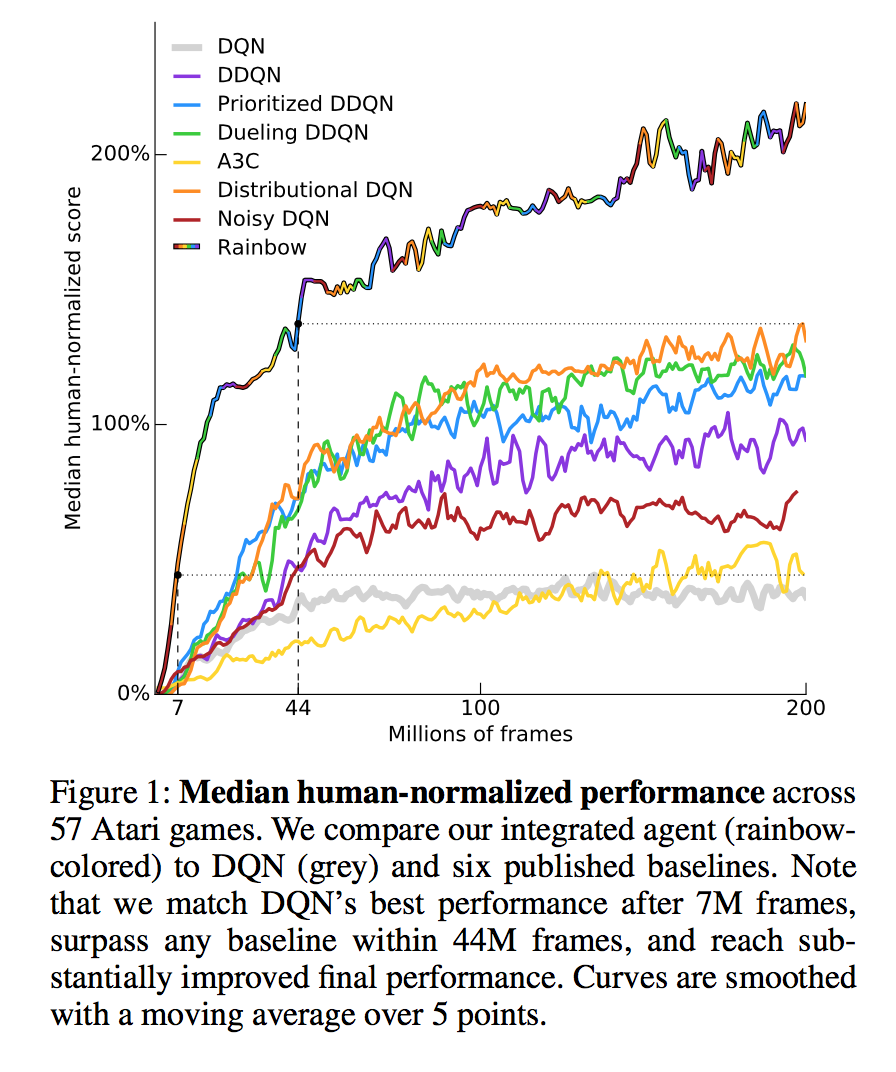
First, the Rainbow system published in October showed the power of combining many recent developments in deep reinforcement learning, including some developments first published in 2016 and some from 2017. This paper had one of the prettiest figures of the year, in my view, which I’m reproducing below, but it fell short of 300% (though I think it’s pretty reasonable to guess that by running it longer, or adding a few more bells and whistles like those discussed in the paper, that might have happened). While not settling this forecast, Rainbow will play a role in resolving another forecast later in this post.
What happened: There was a lot of progress in Atari AI this year. For a more comprehensive summary of algorithmic improvements bearing on Atari progress in the past few years, as well as remaining limitations, see e.g. this, this, and this. I’ll mention two developments of particular relevance here.
First, the Rainbow system published in October showed the power of combining many recent developments in deep reinforcement learning, including some developments first published in 2016 and some from 2017. This paper had one of the prettiest figures of the year, in my view, which I’m reproducing below, but it fell short of 300% (though I think it’s pretty reasonable to guess that by running it longer, or adding a few more bells and whistles like those discussed in the paper, that might have happened). While not settling this forecast, Rainbow will play a role in resolving another forecast later in this post.
Second, the recently announced Ape-X system blew away previous results by scaling up earlier agent elements, but with a different approach for decentralization (decentralized actors send useful memories, rather than gradients, to a central learner). I’ll return to whether this should count below, because it uses a lot of compute, but taking it at face value, it clearly validates the first and second forecasts by attaining a 434% median score. See below:
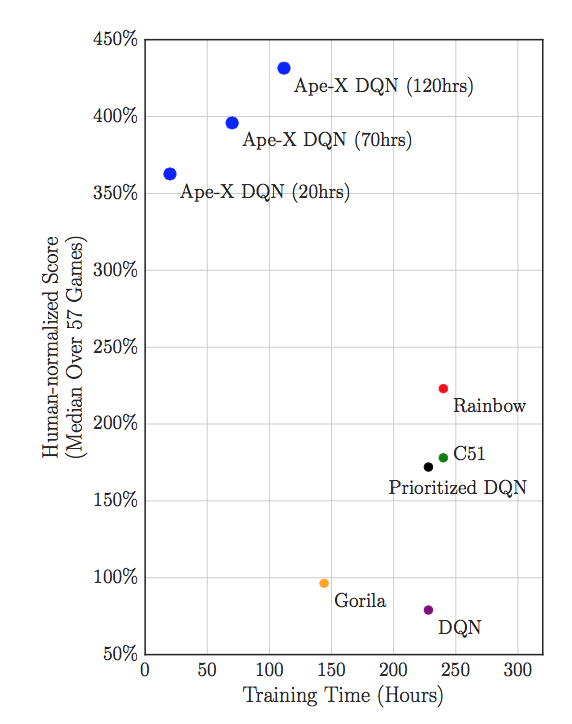
How the forecast was resolved: My own interpretation of the papers plus the independent conclusion of Marc Bellemare (with a big caveat to be discussed further below in the Sidenote on Compute). This resolution method applies to all of the Atari forecasts discussed below.
Score: True
Best median Atari score between 400 and 500% at end of 2017 (confidence: 60%)
See above.
Score: True
Best mean Atari score between 1500% and 4000% at end of 2017 (confidence: 60%)
See above for general discussion, and here for an example of some >1500% mean scores reported in 2017. I believe there might be others, and for several recent papers, the mean was not reported but it would likely be very high given the median score).
Score: True
Sidenote on Compute
For all of the above 3 forecasts, the forecast was resolved as true, but could have been resolved as false if one only considered results that used the same amount of compute as earlier papers. Marc Bellemare writes (personal communication):
“Ape-X results are the best available, as far as I know. This said, [asynchronous] methods use significantly more computational power, so comparing to previous approaches to determine AI technology progress is probably not completely informative -- it's more measuring the availability of resources to AI researchers. On the other hand, there is a case to be made for making these methods work on large distributed systems. …
If comparing compute-for-compute, I believe the answer to be no to all of these, although we have seen significantly progress in all of these metrics (except maybe 3 [Montezuma’s Revenge*]).”
*discussed below
Elaborating on Marc’s point, Ape-X, which plausibly resolved the first two forecasts positively, used a large amount of computing power and a large amount of frames (experiences) per game. The closest median score to 300% that I’m aware of using comparable resources to 2016 papers is Rainbow, at 223% (I exclude UNREAL due to per-game hyperparameter tuning). Likewise, the high mean scores mentioned above use a bit more data than is typical (300 million game frames vs. e.g. 100 or 200 million).
So, as originally stated (without a compute caveat), the forecasts above were all true, but without this caveat, one might be mislead into thinking more progress occurred than there actually was. Thanks to Marc for raising this issue.
We will return to the efficiency issue below in the context of another forecast, and note that I will not always be so generous in interpreting my forecasts charitably (see e.g. Montezuma’s Revenge and StarCraft below); I hope I’m being reasonably objective on average.
No human-level or superintelligent AI (confidence: 95%)
What I meant: Specifically, I said:
“By the end of 2017, there will still be no broadly human-level AI. No leader of a major AI lab will claim to have developed such a thing, there will be recognized deficiencies in common sense reasoning (among other things) in existing AI systems, fluent all-purpose natural language will still not have been achieved, etc.”
This was a bit of a freebie, unless you’re an extreme outlier in views about the future of AI. But I think it’s good to have a range of forecasts in the mix, including confident ones.
What happened: Nothing that would call this forecast’s truth (over the 2017 timeframe) into question, though AI progress occurred, including many efforts aimed at making more general-purpose AI systems.
How it was resolved: Paying attention to the field.
Score: True
Superhuman Montezuma’s Revenge AI (confidence: 70%)
What I meant: I said: “[B]y the end of the year, there will be algorithms that achieve significantly greater than DeepMind’s “human-level” threshold for performance on Montezuma’s Revenge (75% of a professional game tester’s score). Already, there are scores in that ballpark. By superhuman, let’s say that the score will be over 120%.”
Notably, I did not say anything about average vs. best case performance, which bears on the resolution question below.
What happened: A bit of progress, but less than I expected. I noticed after making this forecast that even in 2016, there was a paper (by Marc, actually) in which a single seed of a system achieved well over 120%, but not in a way that was reproducible across different random seeds and hyperparameters - the hard exploration problem here remains unsolved, for now. Typically people report some sort of average of runs, so I won’t count that, and nothing else reliably surpassed 120% Montezuma’s Revenge this year to my knowledge.
How it was resolved: See Atari resolution methods above (my and Marc’s judgment).
Score: False
Superhuman Labyrinth performance (confidence: 60%)
What I meant: “Labyrinth is another environment that DeepMind uses for AI evaluation, and which affords human-normalized performance evaluation. Already, the UNREAL agent tests at 92% median and 87% mean. So I’ll use the same metric as above for Montezuma’s Revenge (superhuman=120%) and say that both mean and median will be superhuman for the tasks DeepMind has historically used.”
What happened: A few papers reported improved Labyrinth (aka DeepMind Lab) results. I believe the highest results were attained with the Population-Based Training (PBT) method layered on top of the UNREAL agent. My understanding from the relevant papers is that the PBT paper uses 2 Labyrinth tasks that the UNREAL paper did not. After subtracting those 2 tasks, so that we’re comparing the same set of 13 tasks, the mean and median (my calculations) are 165 and 133.5%, respectively. Note that this differs from the “average” (presumably median) figure used in the PBT paper, which includes 2 tasks I excluded which were not widely used when I made my forecast.
How it was resolved: I analyzed the relevant papers as described above. Note that I could have counted this as two separate forecasts (mean and median), but didn’t as it was originally listed as one.
Score: True
Impressive transfer learning (confidence: 70%)
What I meant: “Something really impressive in transfer learning will be achieved in 2017, possibly involving some of the domains above, possibly involving Universe. Sufficient measures of “really impressive” include Science or Nature papers, keynote talks at ICML or ICLR on the achievement, widespread tech media coverage, or 7 out of 10 experts (chosen by someone other than me) agreeing that it’s really impressive.”
What happened: A lot of cool results were published in the transfer learning area in 2017, but no one development in particular rose to the level of “really impressive” to a large swathe of the relevant community. This is my understanding based on talking to some folks and especially the comments of Sebastian Ruder and his estimate of what other experts would say. In retrospect, as discussed further below, I think I based this forecast too much on transfer learning being much-hyped as an area for immediate work in 2016--it’s a harder problem than I realized.
How it was resolved: I asked Sebastian to evaluate this, and he said many thoughtful things--I recommend you read the thread in full: https://twitter.com/seb_ruder/status/948403531765067776 In further discussion, Sebastian wrote, “I think that most would agree that there was significant progress, but as that's true for most areas in DL and as I think it'd be harder for them to agree on a particular achievement IMO, I'd also suggest failure [of the forecast].”
Score: False
(sub-prediction of the above) Impressive transfer learning aided by EWC or Progressive Nets (confidence: 60%)
This was a minor sub-prediction of the above - that the source of transfer learning progress would be improvements building on elastic weight consolidation or progressive neural networks, two 2016 developments. While both papers were cited in subsequent developments, nothing earth shattering happened. I don’t feel that my Brier score should be further penalized by this failure, though, since it was implicitly conditional on impressive transfer learning happening at all.
Score: N/A
Speech recognition essentially solved (confidence: 60%)
What I meant: “I think progress in speech recognition is very fast, and think that by the end of 2017, that for most recognized benchmarks (say, 7 out of 10 of those suggested by asking relevant experts), greater than human results will have been achieved. This doesn’t imply perfect speech recognition, but better than the average human, and competitive with teams of humans.”
What happened: There has been further progress in speech recognition, but it remains unsolved in its full generality, as argued recently--noisy environments, accents, multiple speakers talking simultaneously, and other factors continue to make this difficult to solve satisfactorily, although there are some additional benchmarks along which superhuman performance has been claimed. Overall, I think this may have been harder than I thought, and that I updated too much on a relevant expert’s bullishness on progress about a year and a half ago. However, it also seems somewhat plausible to me that this was achievable this year with a bigger push on the data front, and I haven’t seen much progress beyond 2016 era size datasets (~20,000 hours or so of transcribed speech). As documented by researchers at Baidu recently in some detail, many deep learning problems seem to exhibit predictable performance improvement as a function of data, and speech might be such a problem, but we won’t know until we have (perhaps) a few hundred thousand hours of data or more. In any case, as was the case last year, I don’t know much about speech recognition, and am not very confident about any of this.
How it was resolved: Absence of any claims to this effect by top labs; the blog post linked to above.
Score: False
No defeat of AlphaGo by human (confidence: 90%)
What I meant: “It has been announced that there will be something new happening related to AlphaGo in the future, and I’m not sure what that looks like. But I’d be surprised if anything very similar to the Seoul version of AlphaGo (that is, one trained with expert data and then self-play—as opposed to one that only uses self-play which may be harder), using similar amounts of hardware, is ever defeated in a 5 game match by a human.”
What happened: The “something new” I mentioned ended up being a match with Ke Jie, among other events that DeepMind put on in China. Ke Jie lost 3-0 to a version pretty similar to the Seoul version of AlphaGo, although at the time AlphaGo Zero also existed, and was trained only from self-play. There is now talk of some sort of Tencent-hosted human versus machine Go match in 2018, but this seems more about publicity than any real prospect that humans will retain supremacy again. If a Tencent-designed AI loses to a human, I am pretty sure it will be the humans behind the machine who are at fault, as strongly superhuman Go performance has been definitively shown to be possible post-AlphaGo Fan, AlphaGo Lee, AlphaGo Master, AlphaGo Zero, and AlphaZero.
How it was resolved: Nothing fancy was needed.
Score: True
StarCraft progress via deep learning (confidence: 60%)
What I meant: “Early results from researchers at Alberta suggest that deep learning can help with StarCraft, though historically this hasn’t played much of if any role in StarCraft competitions. I expect this will change: in the annual StarCraft competition, I expect one of the 3 top performing bots to use deep learning in some way.”
What happened: I’m disappointed in the way that I phrased this forecast, because it’s ambiguous as to whether the StarCraft competition thing is a necessary condition, a sufficient condition, or neither with respect to my overall “StarCraft progress via deep learning” forecast. But for the purpose of being unbiased, I will assume that I meant it as a necessary condition - that is, since the top 3 thing didn’t happened, I was wrong. Note, however, that there was progress on sub-tasks of StarCraft in 2017 with deep learning, and the 4th place contestant in the tournament did use deep learning.
How it was resolved: Looking at the slides describing the tournament results, and not seeing anything about deep learning for the top 3 bots, but seeing something about deep learning for the 4th place contestant.
Score: False
Professional StarCraft player beaten by AI system by end of 2018 (confidence: 50%)
This forecast refers to the end of 2018, and has since been converted into a bet. It hasn’t happened yet, at least based on public information, which is unsurprising (as I obviously would have given less than 50% chance to it happening earlier than the 50% forecast). So this doesn’t affect my Brier score.
More efficient Atari learning (confidence: 70%)
What I meant: “an [AI] agent will be able to get A3C’s [A3C is an algorithm introduced in 2016] score using 5% as much data as A3C”. This would be a 2x improvement over UNREAL, which in turn was a big improvement over previous approaches in terms of the metric in question (median points attain per unit of training frames).
What happened: There was a fair amount of progress in 2017 in the area of efficient deep reinforcement learning, including some work specifically tested in Atari in particular. For example, the Neural Episodic Control algorithm was specifically motivated by a desire to extract maximum value out of early experiences.
How it was resolved: Resolving this was hard based on the data available (see Marc’s comments below), and some eyeballing of graphs and cross-referencing of multiple papers was required. This is partly because papers rarely report exactly what the performance of an algorithm was at many points in the training process, and sometimes other details are left out.
But ultimately, Marc and I both concluded that this threshold was reached with Rainbow. Interestingly, unlike Neural Episodic Control, Rainbow was not primarily designed to have fast learning--it was intended to be a well-rounded system with both rapid learning and good final performance, and to determine how complementary several different methods were (it turns out they’re pretty complimentary). Here’s the same figure from above, comparing Rainbow to A3C among other algorithms:
Score: True
Best median Atari score between 400 and 500% at end of 2017 (confidence: 60%)
See above.
Score: True
Best mean Atari score between 1500% and 4000% at end of 2017 (confidence: 60%)
See above for general discussion, and here for an example of some >1500% mean scores reported in 2017. I believe there might be others, and for several recent papers, the mean was not reported but it would likely be very high given the median score).
Score: True
Sidenote on Compute
For all of the above 3 forecasts, the forecast was resolved as true, but could have been resolved as false if one only considered results that used the same amount of compute as earlier papers. Marc Bellemare writes (personal communication):
“Ape-X results are the best available, as far as I know. This said, [asynchronous] methods use significantly more computational power, so comparing to previous approaches to determine AI technology progress is probably not completely informative -- it's more measuring the availability of resources to AI researchers. On the other hand, there is a case to be made for making these methods work on large distributed systems. …
If comparing compute-for-compute, I believe the answer to be no to all of these, although we have seen significantly progress in all of these metrics (except maybe 3 [Montezuma’s Revenge*]).”
*discussed below
Elaborating on Marc’s point, Ape-X, which plausibly resolved the first two forecasts positively, used a large amount of computing power and a large amount of frames (experiences) per game. The closest median score to 300% that I’m aware of using comparable resources to 2016 papers is Rainbow, at 223% (I exclude UNREAL due to per-game hyperparameter tuning). Likewise, the high mean scores mentioned above use a bit more data than is typical (300 million game frames vs. e.g. 100 or 200 million).
So, as originally stated (without a compute caveat), the forecasts above were all true, but without this caveat, one might be mislead into thinking more progress occurred than there actually was. Thanks to Marc for raising this issue.
We will return to the efficiency issue below in the context of another forecast, and note that I will not always be so generous in interpreting my forecasts charitably (see e.g. Montezuma’s Revenge and StarCraft below); I hope I’m being reasonably objective on average.
No human-level or superintelligent AI (confidence: 95%)
What I meant: Specifically, I said:
“By the end of 2017, there will still be no broadly human-level AI. No leader of a major AI lab will claim to have developed such a thing, there will be recognized deficiencies in common sense reasoning (among other things) in existing AI systems, fluent all-purpose natural language will still not have been achieved, etc.”
This was a bit of a freebie, unless you’re an extreme outlier in views about the future of AI. But I think it’s good to have a range of forecasts in the mix, including confident ones.
What happened: Nothing that would call this forecast’s truth (over the 2017 timeframe) into question, though AI progress occurred, including many efforts aimed at making more general-purpose AI systems.
How it was resolved: Paying attention to the field.
Score: True
Superhuman Montezuma’s Revenge AI (confidence: 70%)
What I meant: I said: “[B]y the end of the year, there will be algorithms that achieve significantly greater than DeepMind’s “human-level” threshold for performance on Montezuma’s Revenge (75% of a professional game tester’s score). Already, there are scores in that ballpark. By superhuman, let’s say that the score will be over 120%.”
Notably, I did not say anything about average vs. best case performance, which bears on the resolution question below.
What happened: A bit of progress, but less than I expected. I noticed after making this forecast that even in 2016, there was a paper (by Marc, actually) in which a single seed of a system achieved well over 120%, but not in a way that was reproducible across different random seeds and hyperparameters - the hard exploration problem here remains unsolved, for now. Typically people report some sort of average of runs, so I won’t count that, and nothing else reliably surpassed 120% Montezuma’s Revenge this year to my knowledge.
How it was resolved: See Atari resolution methods above (my and Marc’s judgment).
Score: False
Superhuman Labyrinth performance (confidence: 60%)
What I meant: “Labyrinth is another environment that DeepMind uses for AI evaluation, and which affords human-normalized performance evaluation. Already, the UNREAL agent tests at 92% median and 87% mean. So I’ll use the same metric as above for Montezuma’s Revenge (superhuman=120%) and say that both mean and median will be superhuman for the tasks DeepMind has historically used.”
What happened: A few papers reported improved Labyrinth (aka DeepMind Lab) results. I believe the highest results were attained with the Population-Based Training (PBT) method layered on top of the UNREAL agent. My understanding from the relevant papers is that the PBT paper uses 2 Labyrinth tasks that the UNREAL paper did not. After subtracting those 2 tasks, so that we’re comparing the same set of 13 tasks, the mean and median (my calculations) are 165 and 133.5%, respectively. Note that this differs from the “average” (presumably median) figure used in the PBT paper, which includes 2 tasks I excluded which were not widely used when I made my forecast.
How it was resolved: I analyzed the relevant papers as described above. Note that I could have counted this as two separate forecasts (mean and median), but didn’t as it was originally listed as one.
Score: True
Impressive transfer learning (confidence: 70%)
What I meant: “Something really impressive in transfer learning will be achieved in 2017, possibly involving some of the domains above, possibly involving Universe. Sufficient measures of “really impressive” include Science or Nature papers, keynote talks at ICML or ICLR on the achievement, widespread tech media coverage, or 7 out of 10 experts (chosen by someone other than me) agreeing that it’s really impressive.”
What happened: A lot of cool results were published in the transfer learning area in 2017, but no one development in particular rose to the level of “really impressive” to a large swathe of the relevant community. This is my understanding based on talking to some folks and especially the comments of Sebastian Ruder and his estimate of what other experts would say. In retrospect, as discussed further below, I think I based this forecast too much on transfer learning being much-hyped as an area for immediate work in 2016--it’s a harder problem than I realized.
How it was resolved: I asked Sebastian to evaluate this, and he said many thoughtful things--I recommend you read the thread in full: https://twitter.com/seb_ruder/status/948403531765067776 In further discussion, Sebastian wrote, “I think that most would agree that there was significant progress, but as that's true for most areas in DL and as I think it'd be harder for them to agree on a particular achievement IMO, I'd also suggest failure [of the forecast].”
Score: False
(sub-prediction of the above) Impressive transfer learning aided by EWC or Progressive Nets (confidence: 60%)
This was a minor sub-prediction of the above - that the source of transfer learning progress would be improvements building on elastic weight consolidation or progressive neural networks, two 2016 developments. While both papers were cited in subsequent developments, nothing earth shattering happened. I don’t feel that my Brier score should be further penalized by this failure, though, since it was implicitly conditional on impressive transfer learning happening at all.
Score: N/A
Speech recognition essentially solved (confidence: 60%)
What I meant: “I think progress in speech recognition is very fast, and think that by the end of 2017, that for most recognized benchmarks (say, 7 out of 10 of those suggested by asking relevant experts), greater than human results will have been achieved. This doesn’t imply perfect speech recognition, but better than the average human, and competitive with teams of humans.”
What happened: There has been further progress in speech recognition, but it remains unsolved in its full generality, as argued recently--noisy environments, accents, multiple speakers talking simultaneously, and other factors continue to make this difficult to solve satisfactorily, although there are some additional benchmarks along which superhuman performance has been claimed. Overall, I think this may have been harder than I thought, and that I updated too much on a relevant expert’s bullishness on progress about a year and a half ago. However, it also seems somewhat plausible to me that this was achievable this year with a bigger push on the data front, and I haven’t seen much progress beyond 2016 era size datasets (~20,000 hours or so of transcribed speech). As documented by researchers at Baidu recently in some detail, many deep learning problems seem to exhibit predictable performance improvement as a function of data, and speech might be such a problem, but we won’t know until we have (perhaps) a few hundred thousand hours of data or more. In any case, as was the case last year, I don’t know much about speech recognition, and am not very confident about any of this.
How it was resolved: Absence of any claims to this effect by top labs; the blog post linked to above.
Score: False
No defeat of AlphaGo by human (confidence: 90%)
What I meant: “It has been announced that there will be something new happening related to AlphaGo in the future, and I’m not sure what that looks like. But I’d be surprised if anything very similar to the Seoul version of AlphaGo (that is, one trained with expert data and then self-play—as opposed to one that only uses self-play which may be harder), using similar amounts of hardware, is ever defeated in a 5 game match by a human.”
What happened: The “something new” I mentioned ended up being a match with Ke Jie, among other events that DeepMind put on in China. Ke Jie lost 3-0 to a version pretty similar to the Seoul version of AlphaGo, although at the time AlphaGo Zero also existed, and was trained only from self-play. There is now talk of some sort of Tencent-hosted human versus machine Go match in 2018, but this seems more about publicity than any real prospect that humans will retain supremacy again. If a Tencent-designed AI loses to a human, I am pretty sure it will be the humans behind the machine who are at fault, as strongly superhuman Go performance has been definitively shown to be possible post-AlphaGo Fan, AlphaGo Lee, AlphaGo Master, AlphaGo Zero, and AlphaZero.
How it was resolved: Nothing fancy was needed.
Score: True
StarCraft progress via deep learning (confidence: 60%)
What I meant: “Early results from researchers at Alberta suggest that deep learning can help with StarCraft, though historically this hasn’t played much of if any role in StarCraft competitions. I expect this will change: in the annual StarCraft competition, I expect one of the 3 top performing bots to use deep learning in some way.”
What happened: I’m disappointed in the way that I phrased this forecast, because it’s ambiguous as to whether the StarCraft competition thing is a necessary condition, a sufficient condition, or neither with respect to my overall “StarCraft progress via deep learning” forecast. But for the purpose of being unbiased, I will assume that I meant it as a necessary condition - that is, since the top 3 thing didn’t happened, I was wrong. Note, however, that there was progress on sub-tasks of StarCraft in 2017 with deep learning, and the 4th place contestant in the tournament did use deep learning.
How it was resolved: Looking at the slides describing the tournament results, and not seeing anything about deep learning for the top 3 bots, but seeing something about deep learning for the 4th place contestant.
Score: False
Professional StarCraft player beaten by AI system by end of 2018 (confidence: 50%)
This forecast refers to the end of 2018, and has since been converted into a bet. It hasn’t happened yet, at least based on public information, which is unsurprising (as I obviously would have given less than 50% chance to it happening earlier than the 50% forecast). So this doesn’t affect my Brier score.
More efficient Atari learning (confidence: 70%)
What I meant: “an [AI] agent will be able to get A3C’s [A3C is an algorithm introduced in 2016] score using 5% as much data as A3C”. This would be a 2x improvement over UNREAL, which in turn was a big improvement over previous approaches in terms of the metric in question (median points attain per unit of training frames).
What happened: There was a fair amount of progress in 2017 in the area of efficient deep reinforcement learning, including some work specifically tested in Atari in particular. For example, the Neural Episodic Control algorithm was specifically motivated by a desire to extract maximum value out of early experiences.
How it was resolved: Resolving this was hard based on the data available (see Marc’s comments below), and some eyeballing of graphs and cross-referencing of multiple papers was required. This is partly because papers rarely report exactly what the performance of an algorithm was at many points in the training process, and sometimes other details are left out.
But ultimately, Marc and I both concluded that this threshold was reached with Rainbow. Interestingly, unlike Neural Episodic Control, Rainbow was not primarily designed to have fast learning--it was intended to be a well-rounded system with both rapid learning and good final performance, and to determine how complementary several different methods were (it turns out they’re pretty complimentary). Here’s the same figure from above, comparing Rainbow to A3C among other algorithms:
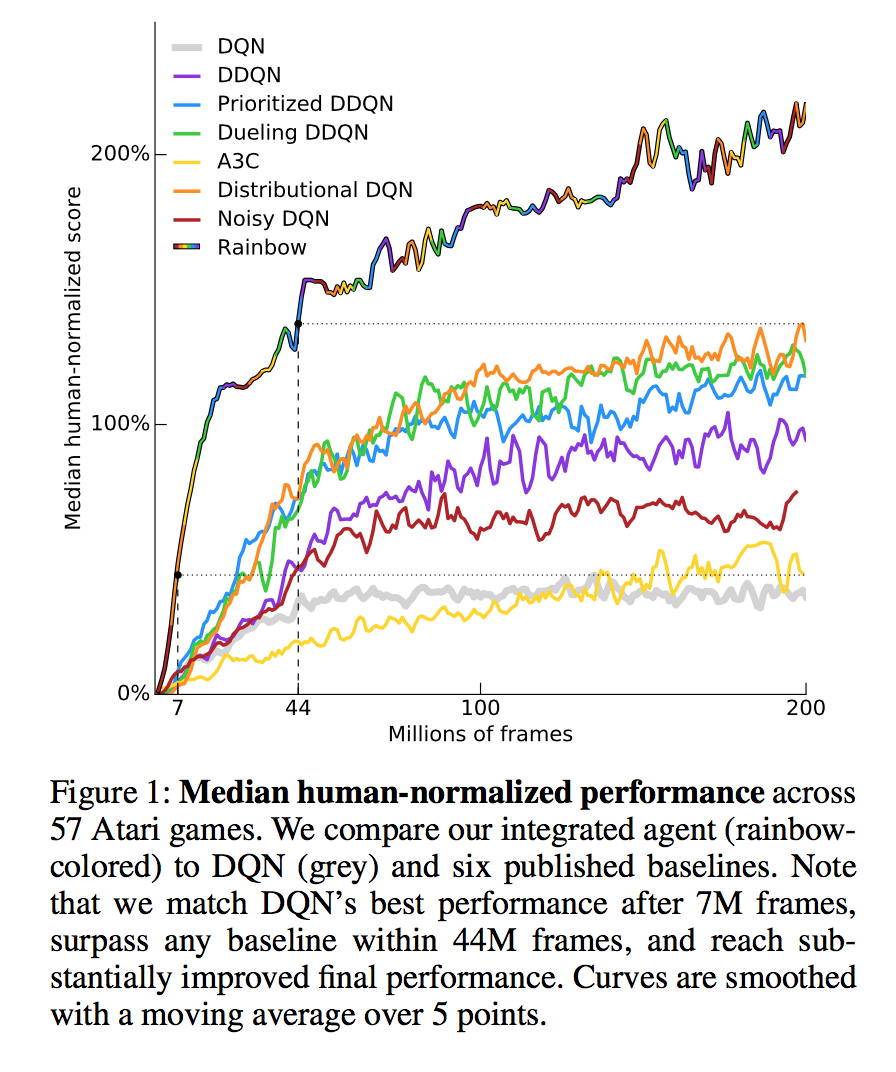
Marc and I ended up interpreting my forecast and resolving it in different ways, though with the same ultimate conclusion. I looked at the above figure and tried to eyeball a point on the Rainbow curve that was about 5% of the way through the 200 million frames - that is, at 10 million frames, a little bit after the dotted vertical at 7%. Based on this eyeballing the Rainbow figure, I concluded that the rainbow-colored line was above the horizontal line (roughly corresponding to A3C’s final performance) by the time 10 million frames is reached - somewhere around the time that the rainbow-colored line is yellow.
Marc, on the other hand, started from A3C’s score (reported elsewhere) and tried to figure out how many frames it used, which was surprisingly difficult (sidenote: Marc is a coauthor on a paper which touches on related evaluation issues). After some back and forth, he wrote:
“I was going by the assumption that A3C consumed about 320M frames of data, which from squinting at the Rainbow graph would put us just short of the 5% mark (but around 7-8%). However, I can't find that # frames figure in the paper. The UNREAL paper has # frames for A3C, but reports mean scores, not median scores. However, if we cross reference the UNREAL learning curve with the A3C mean score reported in Vlad Mnih's 2016 paper, we get a result that suggests about 1 billion frames for A3C, or 180 frames per second -- which sounds about right for the 4 days of training reported in Mnih et al. So you might be right, & I'll adjust my statement to...yes [for this forecast].”
Score: True
_____
Brier Score Calculation
To introduce Brier scores, the means by which I grade my forecasts, I’ll start by excerpting Wikipedia at length:
“The Brier score is a proper score function that measures the accuracy of probabilistic predictions. It is applicable to tasks in which predictions must assign probabilities to a set of mutually exclusive discrete outcomes. The set of possible outcomes can be either binary or categorical in nature, and the probabilities assigned to this set of outcomes must sum to one (where each individual probability is in the range of 0 to 1). It was proposed by Glenn W. Brier in 1950.[1]
...the Brier score measures the mean squared difference between:
Brier scores are calculated in a few different ways, but here I will use the common formulation mentioned above, in which 0 is the best, 1 is the worst, and .25 means you’re essentially forecasting randomly.
Using the common formulation of the Brier score and the scores above, we get:
*drum-roll*
.22
The calculation I plugged into Wolfram Alpha was, if you want to try variations on it:
((.8-1)^2+(.6-1)^2+(.6-1)^2+(.95-1)^2+(.7-0)^2+(.6-1)^2+(.7-0)^2+(.6-0)^2+(.6-0)^2+(.9-1)^2+(.6-0)^2+(.7-1)^2) /12
So, I did better than chance, but barely. Sad! If you changed a few forecasts, it would push it over the line in the other direction (towards being systematically wrong), and it would take several forecasts being flipped in my direction for me to be very (meta-)confident about the future of AI.
Note that Brier scores give an incomplete picture of how good one is at forecasting, however, so being close to .25 doesn't mean I did a horrible job, though I might have. Two other factors are key.
First, some domains are harder to forecast than others - without more analysis of past data and past forecasts, we don’t know how random or predictable AI progress is. I'd be curious to see people do this with datasets like the AI Index and the EFF AI Progress Measurement Project, and I'd like to see more people make and evaluate more forecasts.
Second, Brier scores are about the forecasts you actually made, not other possible forecasts. I could have made many easy forecasts to boost my score. Arguably, the only one was the "no human-level or superintelligent AI" one. With many virtually certain forecasts that turned out correctly, my score would have been closer to 0.
In forecasting tournaments, it's typical to have a range of difficulty levels for questions, and to have many people answer the same questions. That way, you can know whose forecasts are more or less impressive. It also helps to have some base rates of predictability for the domain in question, which, again, we (/I) don't have yet.
Perhaps more importantly than the overall Brier score and the considerations above, though, is what can be learned from the errors.
Patterns
Over the course of the year, as I started to see how forecasts would resolve, I reflected a bit on the sources of errors, and I’ve noticed a few patterns.
First, all of my errors were in the direction of overestimating short-term AI progress. This isn’t super (meta-)surprising to me, since I consider myself pretty bullish about AI, and would be surprised to find myself in the opposite camp. And it is also at least potentially consistent with (Roy) Amara’s Law: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”
I am not sure I should radically update in response to this, though, because first, there is an asymmetry in some of my forecasts such that it would have been impossible to end up underestimating progress (because I didn’t give an upper bound, e.g. with the “superhuman” forecasts for Labyrinth and Montezuma’s Revenge); and second, I’m generally of the belief that there are bigger risks from underestimating technical progress than overestimating it, so if there is an inevitable false positive/false negative tradeoff, I'd like to be slightly on the overestimating side of things. Most of the things we should do in response to expectations of rapid future progress are pretty robustly beneficial (e.g. more safety, ethics, and policy research, or improving social safety nets). But there are cases where that isn’t true, and I made some actual errors that aren’t explainable by the asymmetry point, so I will try to update at least somewhat in response to this pattern and move towards a more calibrated estimate of progress.
Second, in the case of speech recognition and Montezuma’s Revenge, I deferred too much to a small number of relevant experts who were (and are) bullish about AI progress. I suspect part of the reason this happened is that I spend a lot of time talking to people who are concerned about the societal implications of AI, and some such people arrive at their concern based on views about how quickly the technology is progressing relative to society’s speed of preparation (though not all people concerned about societal implications can be described that way or are bullish). I’ll try to take this into account in the future, and more deliberately seek out and associate with skeptics about progress in particular technical areas and with regard to AI in general.
Third, I generally did better in areas that I am familiar with relative to areas I am unfamiliar with (e.g. Atari=familiar, speech recognition=unfamiliar). This isn’t surprising, but worth reflecting more on. Sometimes these factors overlapped (e.g. speech recognition is also an area I’m not that familiar with, and I deferred to someone on it). So I’ll try to limit my forecasts in the future to areas I’ve spent a non-trivial amount of time understanding, like deep reinforcement learning applied to control problems like Atari. I was thinking about making some forecasts for deep reinforcement learning for continuous control problems (like robotics) this year, and now am not so sure about that, because I’ve read such papers less carefully and extensively than Atari-related discrete control papers.
Fourth, the forecasts I made based on quantitative trends did well relative to my forecasts based on other factors like (small n) expert judgment, my gut feelings, and my perception of the hotness of a given research area. There is some evidence from other forecasting domains that quantitative forecasts often fare better than expert judgment. And it’s (in retrospect, at least) unsurprising that hotness isn’t a great signal, since often people work on problems that aren’t just important and timely but also difficult and intellectually interesting, like transfer learning.
Sixth, the problems with evaluating AI progress, which is notoriously difficult, are also applicable to forecasting AI progress. Issues with underreporting of evaluation conditions, for example, made it tricky to determine whether some of the forecasts were right. Some of the ambiguities in my forecast resolutions could have been avoided had I been more specific and spent more time laying out the details, but that would have been more likely to happen in the first place if widely agreed upon evaluation standards were used in AI, so I can’t take all the blame for that.
Conclusion
Overall, I found this retrospective analysis to be humbling, but also helpful. I encourage others to make falsifiable predictions and then look back on them and see what their error sources are.
I’ve definitely grown less confident as a result of doing this Brier score calculation, though I also have become generally more skeptical of other people’s forecasts, since, first, most people don’t make many falsifiable public predictions based on which they can be held accountable and improve their calibration over time, and second, several of my failures were based in part on trusting other people’s judgments. As noted above in the discussion of Brier scores, it's not clear how good or bad my score was, because we (or at least I) don't know what the underlying randomness is in AI progress, and I didn't give myself many freebies.
However, I continue to be impressed, as I was last year, with the power of simple extrapolations, and may make more of these in the future, perhaps using methods derived from the Baidu paper mentioned above, or along the lines I discussed but didn’t follow up on in last year’s post, or using other approaches.
I’m not sure yet whether or when I will write a similar blog post of forecasts for 2018. If I do, I’ll try harder to be more specific about them, since, despite trying hard to make my forecasts falsifiable in 2017, there was still a fair amount of unanticipated wiggle room.
To be continued*!
*confidence level: 70%
____
Recommended Reading
In addition to the various links above, I’m including pretty much the same reading list that I gave last year, for those who want to know more about issues of technological forecasting in general, AI progress measurement in particular, and related issues. I’m adding an additional reference by Morgan on the promise and peril of using expert judgments for policy purposes, and the aforementioned expert survey by some of my colleagues on the longer-term future of AI.
____
Anthony Aguirre et al., Metaculus, website for aggregating forecasts, with a growing number of AI events to be forecasted: http://www.metaculus.com/questions/#?show-welcome=true
Stuart Armstrong et al., “The errors, insights and lessons of famous AI predictions – and what they mean for the future”: www.fhi.ox.ac.uk/wp-content/uploads/FAIC.pdf
Miles Brundage, “Modeling Progress in AI”: https://arxiv.org/abs/1512.05849
Jose Hernandez-Orallo, The Measure of All Minds: Evaluating Natural and Artificial Intelligence: https://www.amazon.com/Measure-All-Minds-Evaluating-Intelligence/dp/1107153018
Doyne Farmer and Francois Lafond, “How predictable is technological progress?”: http://www.sciencedirect.com/science/article/pii/S0048733315001699
Katja Grace et al., “When Will AI Exceed Human Performance? Evidence from AI Experts,” https://arxiv.org/abs/1705.08807
Katja Grace and Paul Christiano et al., AI Impacts (blog on various topics related to the future of AI): http://aiimpacts.org/
M. Granger Morgan, “Use (and abuse) of expert elicitation in support of decision making for public policy,” PNAS, http://www.pnas.org/content/111/20/7176
Luke Muehlhauser, “What should we learn from past AI forecasts?”: http://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/what-should-we-learn-past-ai-forecasts
Alan Porter et al., Forecasting and Management of Technology (second edition): https://www.amazon.com/Forecasting-Management-Technology-Alan-Porter/dp/0470440902
Tom Schaul et al., “Measuring Intelligence through Games”: https://arxiv.org/abs/1109.1314
Marc, on the other hand, started from A3C’s score (reported elsewhere) and tried to figure out how many frames it used, which was surprisingly difficult (sidenote: Marc is a coauthor on a paper which touches on related evaluation issues). After some back and forth, he wrote:
“I was going by the assumption that A3C consumed about 320M frames of data, which from squinting at the Rainbow graph would put us just short of the 5% mark (but around 7-8%). However, I can't find that # frames figure in the paper. The UNREAL paper has # frames for A3C, but reports mean scores, not median scores. However, if we cross reference the UNREAL learning curve with the A3C mean score reported in Vlad Mnih's 2016 paper, we get a result that suggests about 1 billion frames for A3C, or 180 frames per second -- which sounds about right for the 4 days of training reported in Mnih et al. So you might be right, & I'll adjust my statement to...yes [for this forecast].”
Score: True
_____
Brier Score Calculation
To introduce Brier scores, the means by which I grade my forecasts, I’ll start by excerpting Wikipedia at length:
“The Brier score is a proper score function that measures the accuracy of probabilistic predictions. It is applicable to tasks in which predictions must assign probabilities to a set of mutually exclusive discrete outcomes. The set of possible outcomes can be either binary or categorical in nature, and the probabilities assigned to this set of outcomes must sum to one (where each individual probability is in the range of 0 to 1). It was proposed by Glenn W. Brier in 1950.[1]
...the Brier score measures the mean squared difference between:
- The predicted probability assigned to the possible outcomes ...
- The actual outcome ...
Brier scores are calculated in a few different ways, but here I will use the common formulation mentioned above, in which 0 is the best, 1 is the worst, and .25 means you’re essentially forecasting randomly.
Using the common formulation of the Brier score and the scores above, we get:
*drum-roll*
.22
The calculation I plugged into Wolfram Alpha was, if you want to try variations on it:
((.8-1)^2+(.6-1)^2+(.6-1)^2+(.95-1)^2+(.7-0)^2+(.6-1)^2+(.7-0)^2+(.6-0)^2+(.6-0)^2+(.9-1)^2+(.6-0)^2+(.7-1)^2) /12
So, I did better than chance, but barely. Sad! If you changed a few forecasts, it would push it over the line in the other direction (towards being systematically wrong), and it would take several forecasts being flipped in my direction for me to be very (meta-)confident about the future of AI.
Note that Brier scores give an incomplete picture of how good one is at forecasting, however, so being close to .25 doesn't mean I did a horrible job, though I might have. Two other factors are key.
First, some domains are harder to forecast than others - without more analysis of past data and past forecasts, we don’t know how random or predictable AI progress is. I'd be curious to see people do this with datasets like the AI Index and the EFF AI Progress Measurement Project, and I'd like to see more people make and evaluate more forecasts.
Second, Brier scores are about the forecasts you actually made, not other possible forecasts. I could have made many easy forecasts to boost my score. Arguably, the only one was the "no human-level or superintelligent AI" one. With many virtually certain forecasts that turned out correctly, my score would have been closer to 0.
In forecasting tournaments, it's typical to have a range of difficulty levels for questions, and to have many people answer the same questions. That way, you can know whose forecasts are more or less impressive. It also helps to have some base rates of predictability for the domain in question, which, again, we (/I) don't have yet.
Perhaps more importantly than the overall Brier score and the considerations above, though, is what can be learned from the errors.
Patterns
Over the course of the year, as I started to see how forecasts would resolve, I reflected a bit on the sources of errors, and I’ve noticed a few patterns.
First, all of my errors were in the direction of overestimating short-term AI progress. This isn’t super (meta-)surprising to me, since I consider myself pretty bullish about AI, and would be surprised to find myself in the opposite camp. And it is also at least potentially consistent with (Roy) Amara’s Law: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”
I am not sure I should radically update in response to this, though, because first, there is an asymmetry in some of my forecasts such that it would have been impossible to end up underestimating progress (because I didn’t give an upper bound, e.g. with the “superhuman” forecasts for Labyrinth and Montezuma’s Revenge); and second, I’m generally of the belief that there are bigger risks from underestimating technical progress than overestimating it, so if there is an inevitable false positive/false negative tradeoff, I'd like to be slightly on the overestimating side of things. Most of the things we should do in response to expectations of rapid future progress are pretty robustly beneficial (e.g. more safety, ethics, and policy research, or improving social safety nets). But there are cases where that isn’t true, and I made some actual errors that aren’t explainable by the asymmetry point, so I will try to update at least somewhat in response to this pattern and move towards a more calibrated estimate of progress.
Second, in the case of speech recognition and Montezuma’s Revenge, I deferred too much to a small number of relevant experts who were (and are) bullish about AI progress. I suspect part of the reason this happened is that I spend a lot of time talking to people who are concerned about the societal implications of AI, and some such people arrive at their concern based on views about how quickly the technology is progressing relative to society’s speed of preparation (though not all people concerned about societal implications can be described that way or are bullish). I’ll try to take this into account in the future, and more deliberately seek out and associate with skeptics about progress in particular technical areas and with regard to AI in general.
Third, I generally did better in areas that I am familiar with relative to areas I am unfamiliar with (e.g. Atari=familiar, speech recognition=unfamiliar). This isn’t surprising, but worth reflecting more on. Sometimes these factors overlapped (e.g. speech recognition is also an area I’m not that familiar with, and I deferred to someone on it). So I’ll try to limit my forecasts in the future to areas I’ve spent a non-trivial amount of time understanding, like deep reinforcement learning applied to control problems like Atari. I was thinking about making some forecasts for deep reinforcement learning for continuous control problems (like robotics) this year, and now am not so sure about that, because I’ve read such papers less carefully and extensively than Atari-related discrete control papers.
Fourth, the forecasts I made based on quantitative trends did well relative to my forecasts based on other factors like (small n) expert judgment, my gut feelings, and my perception of the hotness of a given research area. There is some evidence from other forecasting domains that quantitative forecasts often fare better than expert judgment. And it’s (in retrospect, at least) unsurprising that hotness isn’t a great signal, since often people work on problems that aren’t just important and timely but also difficult and intellectually interesting, like transfer learning.
Sixth, the problems with evaluating AI progress, which is notoriously difficult, are also applicable to forecasting AI progress. Issues with underreporting of evaluation conditions, for example, made it tricky to determine whether some of the forecasts were right. Some of the ambiguities in my forecast resolutions could have been avoided had I been more specific and spent more time laying out the details, but that would have been more likely to happen in the first place if widely agreed upon evaluation standards were used in AI, so I can’t take all the blame for that.
Conclusion
Overall, I found this retrospective analysis to be humbling, but also helpful. I encourage others to make falsifiable predictions and then look back on them and see what their error sources are.
I’ve definitely grown less confident as a result of doing this Brier score calculation, though I also have become generally more skeptical of other people’s forecasts, since, first, most people don’t make many falsifiable public predictions based on which they can be held accountable and improve their calibration over time, and second, several of my failures were based in part on trusting other people’s judgments. As noted above in the discussion of Brier scores, it's not clear how good or bad my score was, because we (or at least I) don't know what the underlying randomness is in AI progress, and I didn't give myself many freebies.
However, I continue to be impressed, as I was last year, with the power of simple extrapolations, and may make more of these in the future, perhaps using methods derived from the Baidu paper mentioned above, or along the lines I discussed but didn’t follow up on in last year’s post, or using other approaches.
I’m not sure yet whether or when I will write a similar blog post of forecasts for 2018. If I do, I’ll try harder to be more specific about them, since, despite trying hard to make my forecasts falsifiable in 2017, there was still a fair amount of unanticipated wiggle room.
To be continued*!
*confidence level: 70%
____
Recommended Reading
In addition to the various links above, I’m including pretty much the same reading list that I gave last year, for those who want to know more about issues of technological forecasting in general, AI progress measurement in particular, and related issues. I’m adding an additional reference by Morgan on the promise and peril of using expert judgments for policy purposes, and the aforementioned expert survey by some of my colleagues on the longer-term future of AI.
____
Anthony Aguirre et al., Metaculus, website for aggregating forecasts, with a growing number of AI events to be forecasted: http://www.metaculus.com/questions/#?show-welcome=true
Stuart Armstrong et al., “The errors, insights and lessons of famous AI predictions – and what they mean for the future”: www.fhi.ox.ac.uk/wp-content/uploads/FAIC.pdf
Miles Brundage, “Modeling Progress in AI”: https://arxiv.org/abs/1512.05849
Jose Hernandez-Orallo, The Measure of All Minds: Evaluating Natural and Artificial Intelligence: https://www.amazon.com/Measure-All-Minds-Evaluating-Intelligence/dp/1107153018
Doyne Farmer and Francois Lafond, “How predictable is technological progress?”: http://www.sciencedirect.com/science/article/pii/S0048733315001699
Katja Grace et al., “When Will AI Exceed Human Performance? Evidence from AI Experts,” https://arxiv.org/abs/1705.08807
Katja Grace and Paul Christiano et al., AI Impacts (blog on various topics related to the future of AI): http://aiimpacts.org/
M. Granger Morgan, “Use (and abuse) of expert elicitation in support of decision making for public policy,” PNAS, http://www.pnas.org/content/111/20/7176
Luke Muehlhauser, “What should we learn from past AI forecasts?”: http://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/what-should-we-learn-past-ai-forecasts
Alan Porter et al., Forecasting and Management of Technology (second edition): https://www.amazon.com/Forecasting-Management-Technology-Alan-Porter/dp/0470440902
Tom Schaul et al., “Measuring Intelligence through Games”: https://arxiv.org/abs/1109.1314
 RSS Feed
RSS Feed