I have a long-standing interest in understanding how predictable AI progress is, and occasionally make my own forecasts. In this post, I’ll review some of my previous forecasts, make new ones for 2017, and suggest ways that I and others could make better predictions in the future. The purpose of this post is to gather all of the forecasts in one place, keep myself honest/accountable regarding AI forecasting (which was part of the point of making the forecasts in the first place), see what if anything can be learned so far, and encourage others to do more of the above.
For those most interested in the stuff on Atari (my more quantitative forecasts) and my new predictions, and less interested in how my other miscellaneous forecasts fared, just read this blog post. If you want to know more about the process I went through to review all of my other forecasts, and to see how I did on predicting non-Atari things, see this supplemental page.
Atari Forecasts
I’m focusing on these because they’re forecasts about which I’ve thought a lot more than the ones linked to above, and about which I've made more specific data-based forecasts. I also have a lot of data on Atari performance, which will be made public soon.
In early 2016, I made a simple extrapolation of trends in mean and median Atari performance (that is, the best single algorithm’s mean and median score across several dozens games). For both mean and median performance, I made a linear extrapolation and an exponential extrapolation.
For those most interested in the stuff on Atari (my more quantitative forecasts) and my new predictions, and less interested in how my other miscellaneous forecasts fared, just read this blog post. If you want to know more about the process I went through to review all of my other forecasts, and to see how I did on predicting non-Atari things, see this supplemental page.
Atari Forecasts
I’m focusing on these because they’re forecasts about which I’ve thought a lot more than the ones linked to above, and about which I've made more specific data-based forecasts. I also have a lot of data on Atari performance, which will be made public soon.
In early 2016, I made a simple extrapolation of trends in mean and median Atari performance (that is, the best single algorithm’s mean and median score across several dozens games). For both mean and median performance, I made a linear extrapolation and an exponential extrapolation.
Extrapolation of mean/median Atari trends (https://t.co/UYzh8bleNF) - to do seriously, would include error bars... pic.twitter.com/LIZR53MMDI
— Miles Brundage (@Miles_Brundage) April 23, 2016
I also said:
Sidenote: if Atari AI prog. is fairly predictable, median score in the no-op condition will be in the vicinity of 190-250% by end of year.
— Miles Brundage (@Miles_Brundage) May 19, 2016
As the use of the word “sidenote” suggests, this wasn’t that rigorous of a forecast. I just took the available data and assumed the trend was either linear or exponential, and that the future data would be between those two lines. I’ll mention some ways I could have done this better later in this post. But it turned out to be fairly accurate, which I find interesting because it’s often claimed that progress in general AI is nonexistent or impossible to predict. In contrast, I think that general game playing is one of the better (though still partial) measures of cross-domain learning and control we have, and it’s fairly steady over time.
Here is the same plot, with two recent scores added, along with the range I forecasted. The light blue ovals are the data I had as of April, the lines are the same as those I plotted in April, the dark blue stars are very recent scores, and the red oval is the range I forecasted before. Two of DeepMind’s ICLR submissions are roughly at the bottom and top of the range I expected based on eyeballing the graph in April. Obviously, this could have been done more rigorously, but it seems to have been about right.
Here is the same plot, with two recent scores added, along with the range I forecasted. The light blue ovals are the data I had as of April, the lines are the same as those I plotted in April, the dark blue stars are very recent scores, and the red oval is the range I forecasted before. Two of DeepMind’s ICLR submissions are roughly at the bottom and top of the range I expected based on eyeballing the graph in April. Obviously, this could have been done more rigorously, but it seems to have been about right.
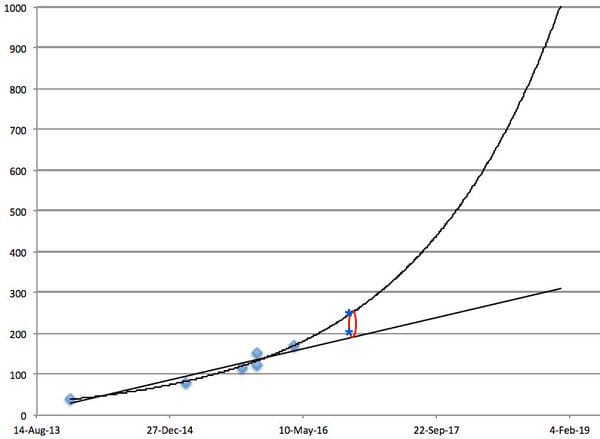
Note that there is eventually some upper bound due to the way evaluation is done (with a fixed amount of time per game), but it may not be reached for a while. And other metrics can be developed (e.g. learning speed, perhaps explored in a future post) which allow for other measures of progress to be projected, even if final scores max out, so I don't see any reason why we couldn't keep making short-term forecasts of benchmarks like this.
Based on the recent data, I think that that we might be seeing an exponential improvement in median scores. The range I gave before was agnostic regarding linear vs. exponential, and recent data points were in the ballpark of both of those lines, but only the higher one really counts since we’re interested in the highest reported score. Using the same sort of simple extrapolation I used before, I pretty strongly (80% confidence) expect that median scores will be between 300 and 500% at the end of 2017 (a range that covers linear progress and a certain speed of exponential progress), and not quite as strongly (60%) expect it to be at the higher end of this, that is, 400-500%, reflecting exponential progress before some eventual asymptote well above human performance.
For mean scores (which I didn’t make a prediction for before), here is what the most recent data (the PGQ paper submitted for ICLR) looks like when added to the graph from April.
Based on the recent data, I think that that we might be seeing an exponential improvement in median scores. The range I gave before was agnostic regarding linear vs. exponential, and recent data points were in the ballpark of both of those lines, but only the higher one really counts since we’re interested in the highest reported score. Using the same sort of simple extrapolation I used before, I pretty strongly (80% confidence) expect that median scores will be between 300 and 500% at the end of 2017 (a range that covers linear progress and a certain speed of exponential progress), and not quite as strongly (60%) expect it to be at the higher end of this, that is, 400-500%, reflecting exponential progress before some eventual asymptote well above human performance.
For mean scores (which I didn’t make a prediction for before), here is what the most recent data (the PGQ paper submitted for ICLR) looks like when added to the graph from April.
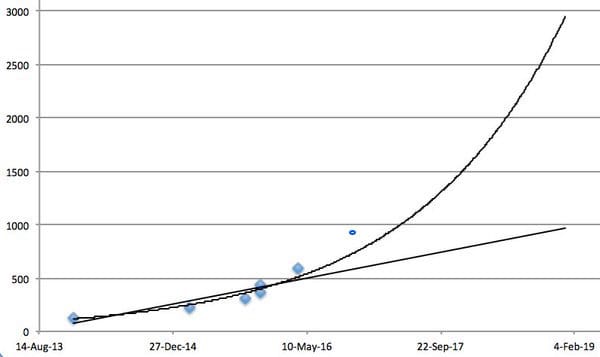
It turns out that mean scores could have been more accurately predicted by an exponential curve—and more specifically, a faster exponential curve than I had come up with. It makes sense that mean scores would grow faster than median scores, but I’m somewhat surprised by how fast mean progress has been. I didn’t make a forecast in April, though, so I’ll rectify that now: by the end of the year, I weakly (60% confidence) expect mean scores to be between 1500% and 4000%. Obviously, that’s a pretty wide range, reflecting uncertainty about the exponent, but even at the low end, it’d be a lot higher than where we are today (877.23%).
Finally, note that these are pretty simple extrapolations and it might turn out that scores asymptote at some level before the end of the year. It seems plausible to me that you could figure out a rough upper bound based on detailed knowledge of the 57 games in question, but I haven't done this.
Conclusion re: Past Forecasts
Overall, I think my forecasts for Atari and the other domains covered (see the supplemental post for more examples of forecasts) were decent and reasonably well-calibrated, but I’m perhaps biased in my interpretation. I haven’t calculated a Brier score for my previous forecasts, but this would be an interesting exercise. Among other things, to do this, I’d have to quantify my implicit levels of confidence in earlier predictions. Perhaps I could have others assign these numbers in order to reduce bias. Since I’m giving confidence levels for my forecasts below, it will be easier to calculate the Brier score for my 2017 predictions.
Also, I think that the success of the median Atari forecast, and the plausibility that the mean forecast could have been better via e.g. error bars, suggests that there may be high marginal returns on efforts to quantify and extrapolate AI progress over the short-term.
Finally, it was a pain to find all of my old forecasts, so in the future, I’ll be putting them in blog posts or using a specific hashtag to make them more easily discoverable in the future.
Present Forecasts
Below are forecasts that I’ve either thought about a lot already, or just came up with in a few minutes for the purpose of this post. These are labeled “present” forecasts because while they’re about the future, they’re relatively weak and shoddy compared to what I or others might do in the future, e.g. with theoretically well-motivated error bars, more rigorous data collection, a wider range of tasks/domains covered, etc. I’ll say a bit about such future forecasts later, but for now I’ll just list a bunch of present forecasts.
First, I’ll just repeat what I said above about Atari.
Best median Atari score between 300 and 500% at end of 2017
Confidence level: 80%
Best mean Atari score between 1500% and 4000% at end of 2017
Confidence level: 60%
No human-level or superintelligent AI
By the end of 2017, there will still be no broadly human-level AI. No leader of a major AI lab will claim to have developed such a thing, there will be recognized deficiencies in common sense reasoning (among other things) in existing AI systems, fluent all-purpose natural language will still not have been achieved, etc.
Confidence level: 95%
Superhuman Montezuma’s Revenge AI
I don’t think this is that provocative to those who follow Atari AI super closely, versus how it may seem to those who are casual observers and have heard that Montezuma’s Revenge is hard for AIs, but I think by the end of the year, there will be algorithms that achieve significantly greater than DeepMind’s “human-level” threshold for performance on Montezuma’s Revenge (75% of a professional game tester’s score). Already, there are scores in that ballpark. By superhuman, let’s say that the score will be over 120%.
Confidence level: 70%
Superhuman Labyrinth performance
Labyrinth is another environment that DeepMind uses for AI evaluation, and which affords human-normalized performance evaluation. Already, the UNREAL agent tests at 92% median and 87% mean. So I’ll use the same metric as above for Montezuma’s Revenge (superhuman=120%) and say that both mean and median will be superhuman for the tasks DeepMind has historically used. I’m not as familiar with Labyrinth as Atari, so am not as confident in this.
Confidence level: 60%
Impressive transfer learning
Something really impressive in transfer learning will be achieved in 2017, possibly involving some of the domains above, possibly involving Universe. Sufficient measures of “really impressive” include Science or Nature papers, keynote talks at ICML or ICLR on the achievement, widespread tech media coverage, or 7 out of 10 experts (chosen by someone other than me) agreeing that it’s really impressive.
Confidence level: 70%
I also weakly predict that progressive neural networks and/or elastic weight consolidation (thanks to Jonathan Yan for suggesting the latter to me) will help with this (60%).
Speech recognition essentially solved
I think progress in speech recognition is very fast, and think that by the end of 2017, that for most recognized benchmarks (say, 7 out of 10 of those suggested by asking relevant experts), greater than human results will have been achieved. This doesn’t imply perfect speech recognition, but better than the average human, and competitive with teams of humans.
Confidence level: 60%
No defeat of AlphaGo by human
It has been announced that there will be something new happening related to AlphaGo in the future, and I’m not sure what that looks like. But I’d be surprised if anything very similar to the Seoul version of AlphaGo (that is, one trained with expert data and then self-play—as opposed to one that only uses self-play which may be harder), using similar amounts of hardware, is ever defeated in a 5 game match by a human.
Confidence level: 90%
StarCraft progress via deep learning
Early results from researchers at Alberta suggest that deep learning can help with StarCraft, though historically this hasn’t played much of if any role in StarCraft competitions. I expect this will change: in the annual StarCraft competition, I expect one of the 3 top performing bots to use deep learning in some way.
Confidence level: 60%
Professional StarCraft player beaten by AI system
I don’t know what the best metric for this is, as there are many ways such a match could occur. I’m also not that confident it will happen next year, but I think I’d be less surprised by it than some people. So partly because I think it’s plausible, and partly because it’s a more interesting prediction than some of the others here, I’ll say that it’ll happen by the end of 2018. I think it is plausible that such an achievement could happen through a combination of deep RL, recent advances in hierarchical learning, scaling up of hardware and researcher effort, and other factors soon-ish, but it's also plausible that other big, longer-term breakthroughs are needed.
Confidence level: 50%
More efficient Atari learning
I haven’t looked super closely at the data on this, but I think there’s pretty fast progress in Atari learning happening with less computational resources. See e.g. this graph of several papers hardware type-adjusted score efficiency (how many points produced per day of CPU, with GPUs counting as 5 units of CPU).
Finally, note that these are pretty simple extrapolations and it might turn out that scores asymptote at some level before the end of the year. It seems plausible to me that you could figure out a rough upper bound based on detailed knowledge of the 57 games in question, but I haven't done this.
Conclusion re: Past Forecasts
Overall, I think my forecasts for Atari and the other domains covered (see the supplemental post for more examples of forecasts) were decent and reasonably well-calibrated, but I’m perhaps biased in my interpretation. I haven’t calculated a Brier score for my previous forecasts, but this would be an interesting exercise. Among other things, to do this, I’d have to quantify my implicit levels of confidence in earlier predictions. Perhaps I could have others assign these numbers in order to reduce bias. Since I’m giving confidence levels for my forecasts below, it will be easier to calculate the Brier score for my 2017 predictions.
Also, I think that the success of the median Atari forecast, and the plausibility that the mean forecast could have been better via e.g. error bars, suggests that there may be high marginal returns on efforts to quantify and extrapolate AI progress over the short-term.
Finally, it was a pain to find all of my old forecasts, so in the future, I’ll be putting them in blog posts or using a specific hashtag to make them more easily discoverable in the future.
Present Forecasts
Below are forecasts that I’ve either thought about a lot already, or just came up with in a few minutes for the purpose of this post. These are labeled “present” forecasts because while they’re about the future, they’re relatively weak and shoddy compared to what I or others might do in the future, e.g. with theoretically well-motivated error bars, more rigorous data collection, a wider range of tasks/domains covered, etc. I’ll say a bit about such future forecasts later, but for now I’ll just list a bunch of present forecasts.
First, I’ll just repeat what I said above about Atari.
Best median Atari score between 300 and 500% at end of 2017
Confidence level: 80%
Best mean Atari score between 1500% and 4000% at end of 2017
Confidence level: 60%
No human-level or superintelligent AI
By the end of 2017, there will still be no broadly human-level AI. No leader of a major AI lab will claim to have developed such a thing, there will be recognized deficiencies in common sense reasoning (among other things) in existing AI systems, fluent all-purpose natural language will still not have been achieved, etc.
Confidence level: 95%
Superhuman Montezuma’s Revenge AI
I don’t think this is that provocative to those who follow Atari AI super closely, versus how it may seem to those who are casual observers and have heard that Montezuma’s Revenge is hard for AIs, but I think by the end of the year, there will be algorithms that achieve significantly greater than DeepMind’s “human-level” threshold for performance on Montezuma’s Revenge (75% of a professional game tester’s score). Already, there are scores in that ballpark. By superhuman, let’s say that the score will be over 120%.
Confidence level: 70%
Superhuman Labyrinth performance
Labyrinth is another environment that DeepMind uses for AI evaluation, and which affords human-normalized performance evaluation. Already, the UNREAL agent tests at 92% median and 87% mean. So I’ll use the same metric as above for Montezuma’s Revenge (superhuman=120%) and say that both mean and median will be superhuman for the tasks DeepMind has historically used. I’m not as familiar with Labyrinth as Atari, so am not as confident in this.
Confidence level: 60%
Impressive transfer learning
Something really impressive in transfer learning will be achieved in 2017, possibly involving some of the domains above, possibly involving Universe. Sufficient measures of “really impressive” include Science or Nature papers, keynote talks at ICML or ICLR on the achievement, widespread tech media coverage, or 7 out of 10 experts (chosen by someone other than me) agreeing that it’s really impressive.
Confidence level: 70%
I also weakly predict that progressive neural networks and/or elastic weight consolidation (thanks to Jonathan Yan for suggesting the latter to me) will help with this (60%).
Speech recognition essentially solved
I think progress in speech recognition is very fast, and think that by the end of 2017, that for most recognized benchmarks (say, 7 out of 10 of those suggested by asking relevant experts), greater than human results will have been achieved. This doesn’t imply perfect speech recognition, but better than the average human, and competitive with teams of humans.
Confidence level: 60%
No defeat of AlphaGo by human
It has been announced that there will be something new happening related to AlphaGo in the future, and I’m not sure what that looks like. But I’d be surprised if anything very similar to the Seoul version of AlphaGo (that is, one trained with expert data and then self-play—as opposed to one that only uses self-play which may be harder), using similar amounts of hardware, is ever defeated in a 5 game match by a human.
Confidence level: 90%
StarCraft progress via deep learning
Early results from researchers at Alberta suggest that deep learning can help with StarCraft, though historically this hasn’t played much of if any role in StarCraft competitions. I expect this will change: in the annual StarCraft competition, I expect one of the 3 top performing bots to use deep learning in some way.
Confidence level: 60%
Professional StarCraft player beaten by AI system
I don’t know what the best metric for this is, as there are many ways such a match could occur. I’m also not that confident it will happen next year, but I think I’d be less surprised by it than some people. So partly because I think it’s plausible, and partly because it’s a more interesting prediction than some of the others here, I’ll say that it’ll happen by the end of 2018. I think it is plausible that such an achievement could happen through a combination of deep RL, recent advances in hierarchical learning, scaling up of hardware and researcher effort, and other factors soon-ish, but it's also plausible that other big, longer-term breakthroughs are needed.
Confidence level: 50%
More efficient Atari learning
I haven’t looked super closely at the data on this, but I think there’s pretty fast progress in Atari learning happening with less computational resources. See e.g. this graph of several papers hardware type-adjusted score efficiency (how many points produced per day of CPU, with GPUs counting as 5 units of CPU).
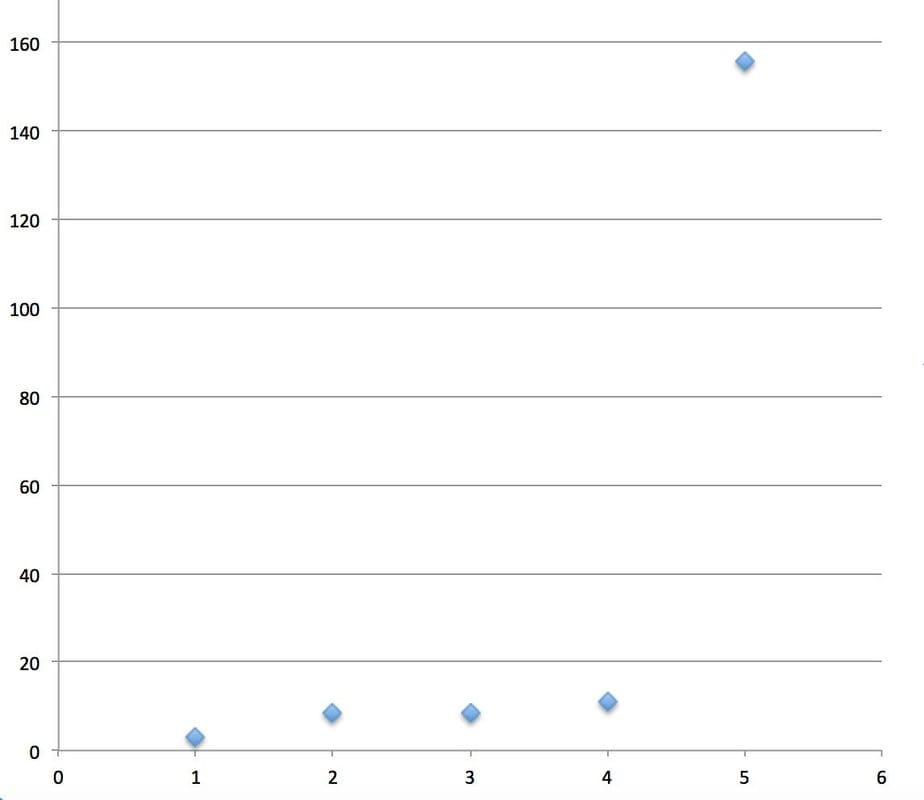
The big jump is from A3C, which learned relatively quickly using CPUs, vs. days of GPUs on earlier systems. Moreover, the UNREAL agent learns approximately 10x faster than A3C. So by the end of 2017, I’ll say that learning efficiency will be twice as good as that: an agent will be able to get A3C’s score using 5% as much data as A3C. Considering how big a jump happened with just one paper (UNREAL), this seems conservative, but as with the mean score forecast above, it’s still a big jump over what exists today so is arguably a non-trivial prediction.
Confidence level: 70%
Future Forecasts
There is a lot of room for improvement in the methodology and scale of AI forecasting.
One can use error bars based on the variance of technological progress rates and the number of data points available, as suggested by Farmer and Lafond (that paper is included in the list of resources below).
There are also many more tasks for which one could gather data and make forecasts. For example, one area that I think is worth looking at is progress in continuous control. It’s an area of real-world importance (specifically, robotics for manufacturing and service applications), and there’s a lot of data available for tasks in MuJoCo in terms of scores, data efficiency, etc. That’s a case where further research and forecasting/subsequent evaluation of forecasts could be valuable not only for improving our knowledge of AI’s predictability, but also our early warning system for economic impacts of AI. Likewise for some NLP tasks, possibly, but I’m less familiar with the nature of those tasks.
A lot of my forecasts are about technical things rather than the social impact of AI, and the latter is also ripe for well-grounded forecasting. Right now, the people making forecasts of AI adoption are people like Forrester Research, who sell $500 reports, and aren’t transparent about methods (or at least, I don’t know how transparent they are since I can’t afford their reports). It might be useful to have better vetted, and/or crowdsourced, free alternatives to such analyses. Topics on which one could make forecasts include AI adoption, publication rates, relative performance of labs/companies/countries, dataset sizes, job displacement scales/types, etc.
The literature on AI forecasting is pretty sparse at the moment, though there are many resources to draw on (listed below). A lot of things can be improved. But in the future, besides growing this literature on its own terms, I think it’d be good for there to be stronger connections between AI forecasts and the literature on technological change in general. For example, Bloom et al. had a very interesting paper recently called “Are Ideas Getting Harder to Find?” which suggested that fast technological improvement has occurred alongside fast growth in the inputs to that improvement (researcher hours). One could ask the question of how much AI progress we’re getting for a given amount of input, how much those inputs (researchers, data, hardware, etc.) are growing, and why/under what conditions AI progress is predictable at all.
Recommended Reading:
Stuart Armstrong et al., “The errors, insights and lessons of famous AI predictions – and what they mean for the future”: www.fhi.ox.ac.uk/wp-content/uploads/FAIC.pdf
Miles Brundage, “Modeling Progress in AI”: https://arxiv.org/abs/1512.05849
Jose Hernandez-Orallo, The Measure of All Minds: Evaluating Natural and Artificial Intelligence: https://www.amazon.com/Measure-All-Minds-Evaluating-Intelligence/dp/1107153018
Doyne Farmer and Francois Lafond, “How predictable is technological progress?”: http://www.sciencedirect.com/science/article/pii/S0048733315001699
Katja Grace and Paul Christiano et al., AI Impacts (blog on various topics related to the future of AI): http://aiimpacts.org/
Anthony Aguirre et al., Metaculus, website for aggregating forecasts, with a growing number of AI events to be forecasted: http://www.metaculus.com/questions/#?show-welcome=true
Luke Muehlhauser, “What should we learn from past AI forecasts?”: http://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/what-should-we-learn-past-ai-forecasts
Alan Porter et al., Forecasting and Management of Technology (second edition): https://www.amazon.com/Forecasting-Management-Technology-Alan-Porter/dp/0470440902
Tom Schaul et al., “Measuring Intelligence through Games”: https://arxiv.org/abs/1109.1314
Acknowledgments: Thanks to various commenters on Twitter for suggesting different considerations for new forecasts, various people for encouraging me to keep doing AI forecasting and writing it up (sorry it took so long to make this post!), and Allan Dafoe for comments on an earlier version of this post.
Confidence level: 70%
Future Forecasts
There is a lot of room for improvement in the methodology and scale of AI forecasting.
One can use error bars based on the variance of technological progress rates and the number of data points available, as suggested by Farmer and Lafond (that paper is included in the list of resources below).
There are also many more tasks for which one could gather data and make forecasts. For example, one area that I think is worth looking at is progress in continuous control. It’s an area of real-world importance (specifically, robotics for manufacturing and service applications), and there’s a lot of data available for tasks in MuJoCo in terms of scores, data efficiency, etc. That’s a case where further research and forecasting/subsequent evaluation of forecasts could be valuable not only for improving our knowledge of AI’s predictability, but also our early warning system for economic impacts of AI. Likewise for some NLP tasks, possibly, but I’m less familiar with the nature of those tasks.
A lot of my forecasts are about technical things rather than the social impact of AI, and the latter is also ripe for well-grounded forecasting. Right now, the people making forecasts of AI adoption are people like Forrester Research, who sell $500 reports, and aren’t transparent about methods (or at least, I don’t know how transparent they are since I can’t afford their reports). It might be useful to have better vetted, and/or crowdsourced, free alternatives to such analyses. Topics on which one could make forecasts include AI adoption, publication rates, relative performance of labs/companies/countries, dataset sizes, job displacement scales/types, etc.
The literature on AI forecasting is pretty sparse at the moment, though there are many resources to draw on (listed below). A lot of things can be improved. But in the future, besides growing this literature on its own terms, I think it’d be good for there to be stronger connections between AI forecasts and the literature on technological change in general. For example, Bloom et al. had a very interesting paper recently called “Are Ideas Getting Harder to Find?” which suggested that fast technological improvement has occurred alongside fast growth in the inputs to that improvement (researcher hours). One could ask the question of how much AI progress we’re getting for a given amount of input, how much those inputs (researchers, data, hardware, etc.) are growing, and why/under what conditions AI progress is predictable at all.
Recommended Reading:
Stuart Armstrong et al., “The errors, insights and lessons of famous AI predictions – and what they mean for the future”: www.fhi.ox.ac.uk/wp-content/uploads/FAIC.pdf
Miles Brundage, “Modeling Progress in AI”: https://arxiv.org/abs/1512.05849
Jose Hernandez-Orallo, The Measure of All Minds: Evaluating Natural and Artificial Intelligence: https://www.amazon.com/Measure-All-Minds-Evaluating-Intelligence/dp/1107153018
Doyne Farmer and Francois Lafond, “How predictable is technological progress?”: http://www.sciencedirect.com/science/article/pii/S0048733315001699
Katja Grace and Paul Christiano et al., AI Impacts (blog on various topics related to the future of AI): http://aiimpacts.org/
Anthony Aguirre et al., Metaculus, website for aggregating forecasts, with a growing number of AI events to be forecasted: http://www.metaculus.com/questions/#?show-welcome=true
Luke Muehlhauser, “What should we learn from past AI forecasts?”: http://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/what-should-we-learn-past-ai-forecasts
Alan Porter et al., Forecasting and Management of Technology (second edition): https://www.amazon.com/Forecasting-Management-Technology-Alan-Porter/dp/0470440902
Tom Schaul et al., “Measuring Intelligence through Games”: https://arxiv.org/abs/1109.1314
Acknowledgments: Thanks to various commenters on Twitter for suggesting different considerations for new forecasts, various people for encouraging me to keep doing AI forecasting and writing it up (sorry it took so long to make this post!), and Allan Dafoe for comments on an earlier version of this post.

 RSS Feed
RSS Feed